
Ganz gleich, ob Sie eine neue App entwickeln oder bereits einen Dienst mit hohem Traffic betreiben – in dieser Anleitung finden Sie Einblicke und Empfehlungen zur reibungslosen Skalierung mit FCM. Mit diesen Konzepten und Praktiken können Sie negative Auswirkungen vermeiden, wenn Sie große Mengen an Nachrichten senden müssen.
Wichtige Begriffe und Konzepte
Nachrichtenanfrage: Eine FCM-Nachrichtenanfrage, die synonym mit „Anfrage“, „Nachricht“ oder „Abfrage“ verwendet wird.
Anfragen pro Sekunde (RPS): Ein Messwert zur Beschreibung der Rate eingehender Anfragen an FCM, der synonym mit „Abfragen pro Sekunde (QPS)“ verwendet wird.
Kontingent-Tokens, Token-Buckets und Aufladungen: Wenn Sie Nachrichten über die FCM HTTP v1 API senden, verbraucht jede Anfrage in einem bestimmten Zeitraum ein zugewiesenes Kontingent-Token. Dieser Zeitraum wird als „Token-Bucket“ bezeichnet und wird am Ende des Zeitraums wieder aufgefüllt. Beispiel: Die HTTP v1 API weist für jeden 1-Minuten-Token-Bucket 600.000 Kontingent-Tokens zu, die am Ende jedes 1-Minuten-Zeitraums wieder aufgefüllt werden.
Serverseitige Drosselung: Wenn das Trafficvolumen die Kapazität des FCM-Dienstes
übersteigt, werden Anfragen, die die Kapazität übersteigen, abgelehnt, um den eingehenden Traffic
zu begrenzen. Es können 429-Fehlerantworten mit retry-after-Headern zurückgegeben werden, um anzugeben, dass Sie einen bestimmten Zeitraum warten sollten, bevor Sie die Anfrage noch einmal senden.
Clientseitige Drosselung: Wenn bei Clients Anfragen fehlschlagen, eine hohe Latenz auftritt,
oder 429 Fehler auftreten, sollten sie den ausgehenden Traffic freiwillig begrenzen, um eine Überlastung zu vermeiden.
Exponentieller Backoff: Wenn Sie Fehler wiederholen, fügen Sie exponentiell steigende Zeitverzögerungen hinzu. Beispiel: 1 s, 2 s, 4 s, 8 s, 16 s, 32 s usw.
Jittering: Vermeiden Sie es, Anfragen in exakten Intervallen zu wiederholen. Beim Jittering variieren Sie die Verzögerungen bei Wiederholungen durch einen Zufallsprozess, um sie gleichmäßig über die Zeit zu verteilen (z. B. 0,9 s, 2,3 s, 4,1 s, 8,5 s, 17,9 s, 34,7 s).
Wiederholungsverstärkung: Wenn fehlgeschlagene Anfragen ohne exponentiellen Backoff/Jittering wiederholt werden, sammeln sie sich oft an und erhöhen die laufende Trafficlast, wodurch Probleme mit der Trafficüberlastung möglicherweise verstärkt werden.
Das Problem: Trafficspitzen
FCM verarbeitet Millionen von Anfragen pro Sekunde (RPS). Der größte Faktor für systemische Überlastung, Latenzprobleme und Ausfälle sind Trafficspitzen.
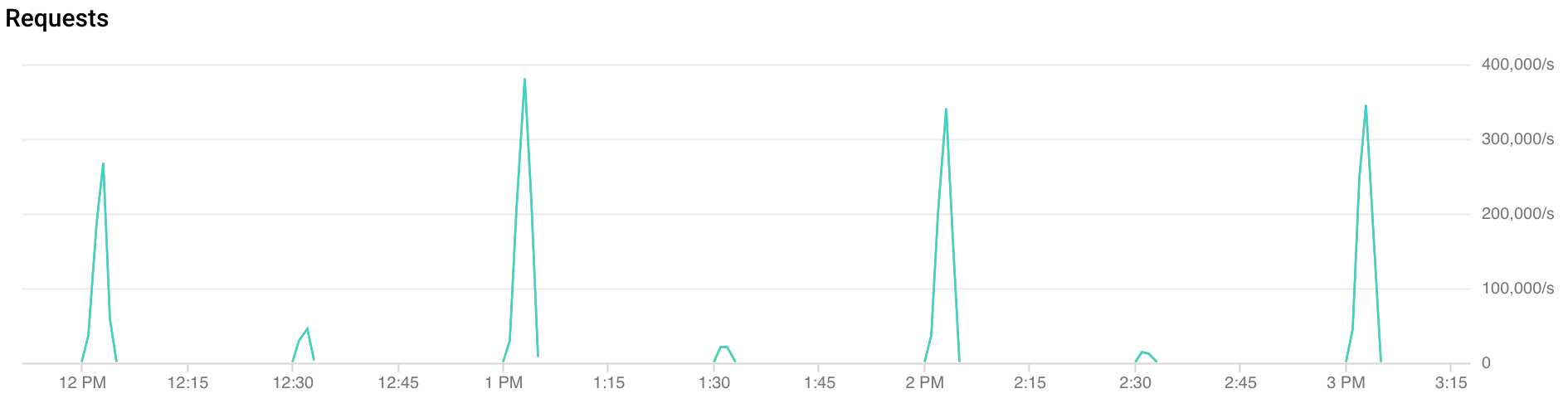
Was ist sprunghafter Traffic?
Es gibt verschiedene Arten von Trafficspitzen.
Spitzen zur vollen Stunde: FCM erhält in den ersten 30 Sekunden bis 2 Minuten jeder Stunde mehr als doppelt so viel Traffic. Ähnliche, wenn auch geringere Spitzen werden auch zur halben und viertel Stunde beobachtet (Beispiele: 00:15, 00:30, 00:45).
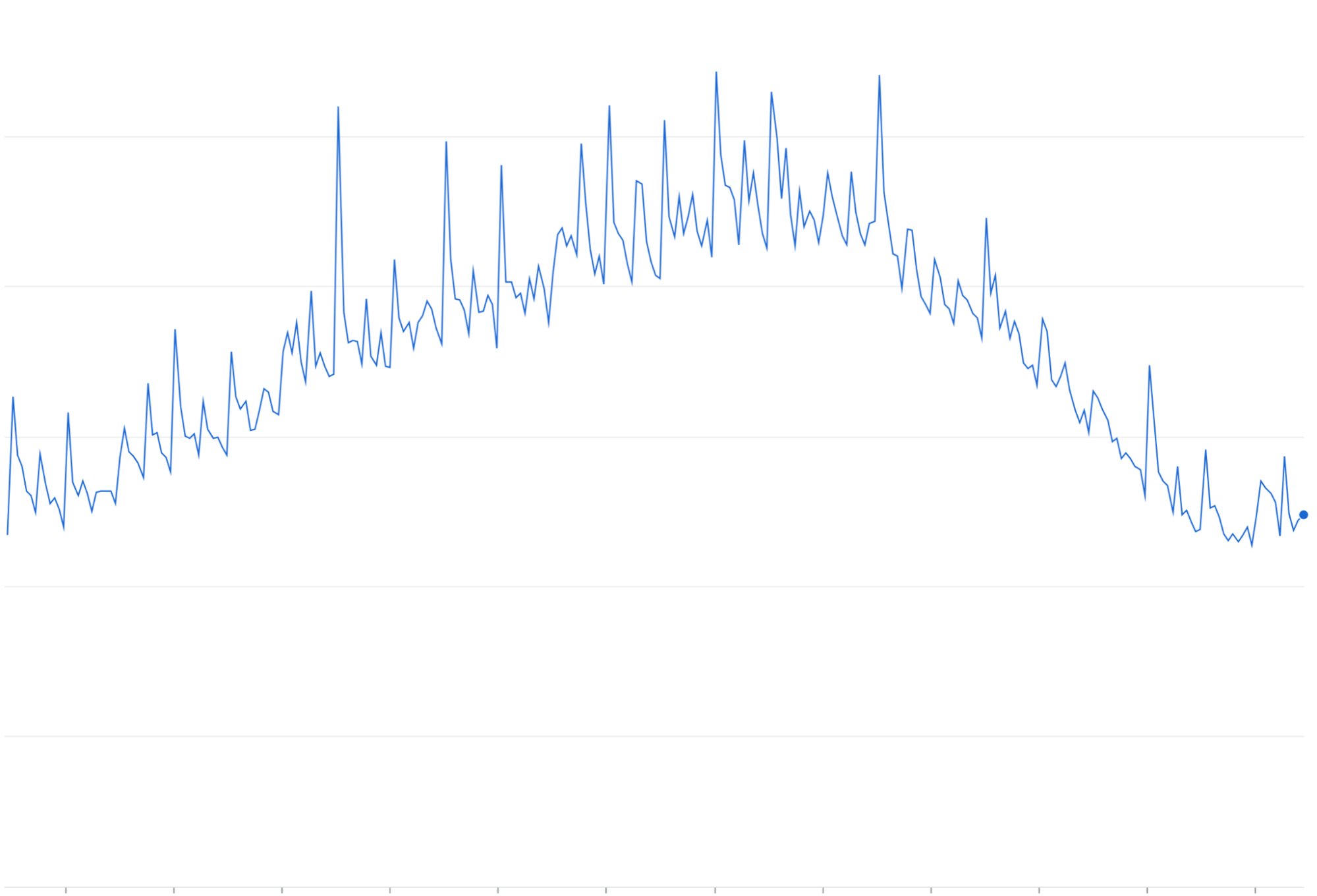
Wiederholungsverstärkung: Wenn Sie fehlgeschlagene oder zeitlich begrenzte Anfragen ohne exponentiellen Backoff wiederholen, können sich wiederholte Trafficwellen zusätzlich zu den bestehenden Trafficspitzen ansammeln.
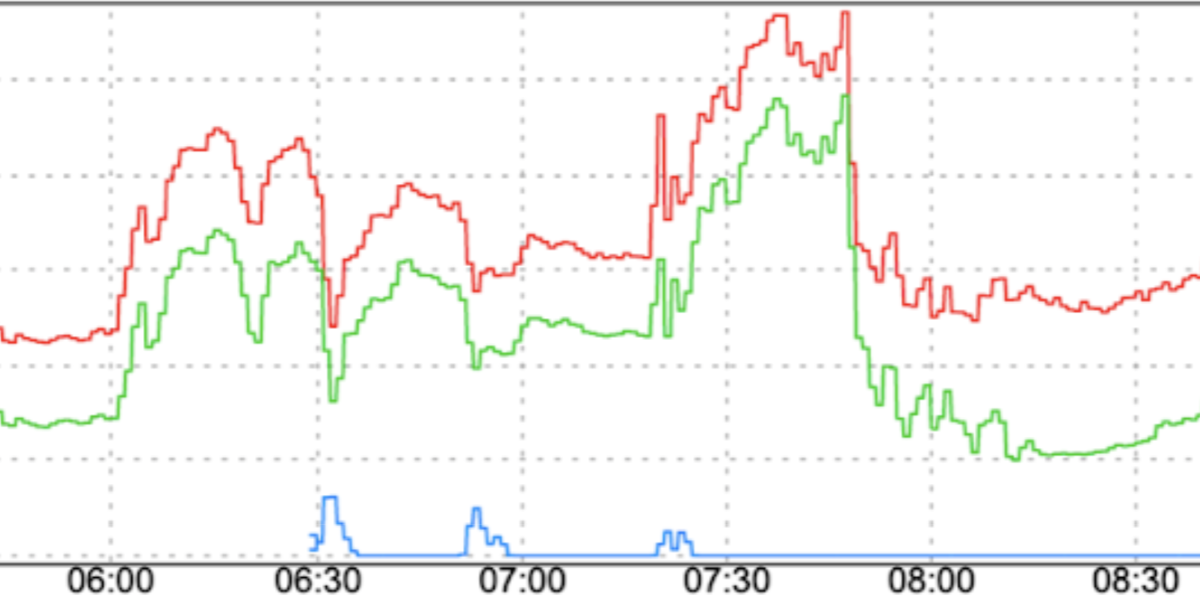
Abrupte Änderungen des Trafficmusters: Wenn Sie neuen Traffic an FCM weiterleiten oder Traffic ohne glättende Faktoren wie eine schrittweise Erhöhung über Regionen hinweg zu FCM verschieben, können Spitzen auftreten.
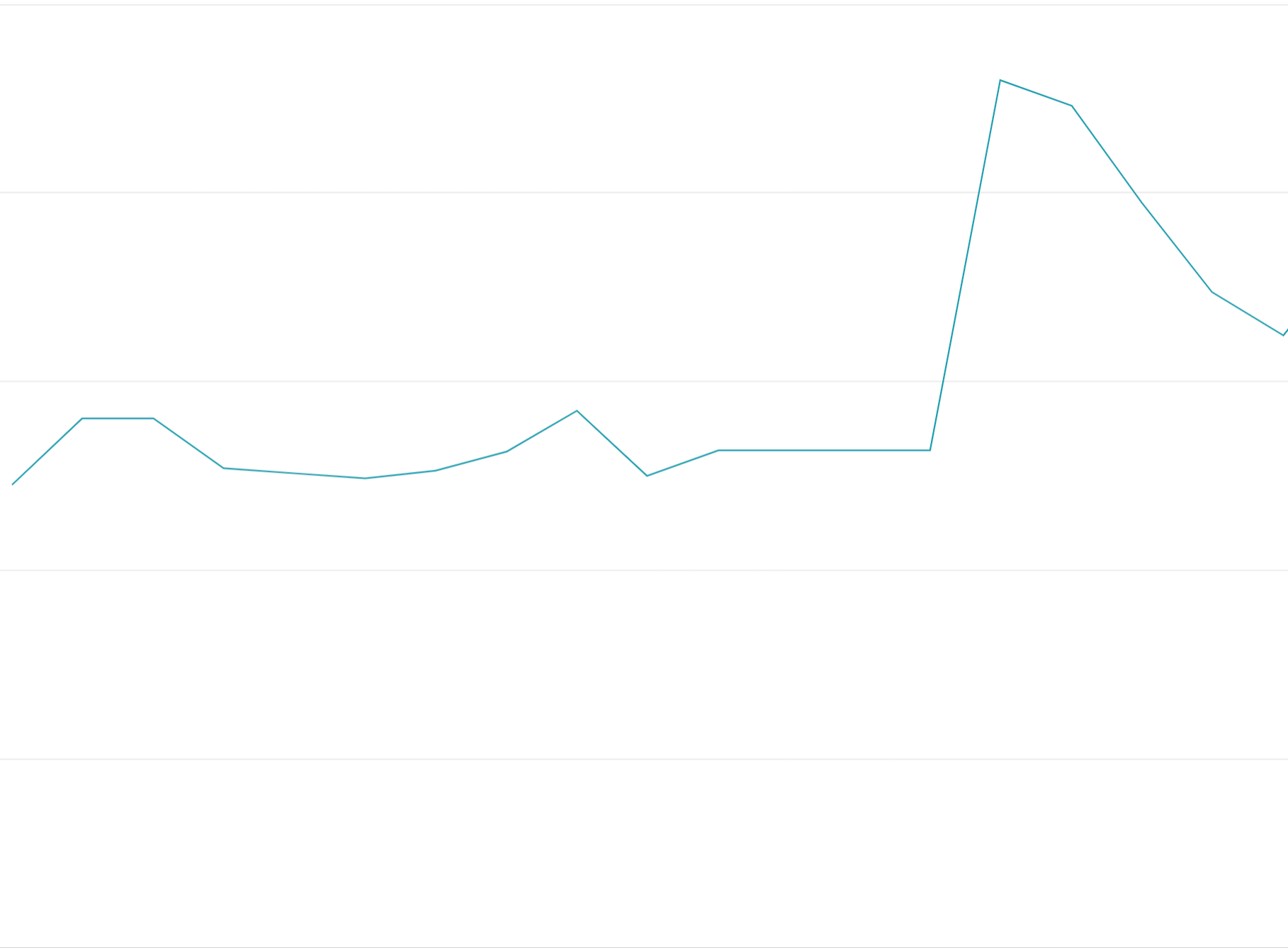
Vorzeitige Nutzung von Kontingent-Tokens: Wenn Sie alle Kontingent-Tokens zu Beginn der Kontingentzeiträume verbrauchen, anstatt die Anfragen gleichmäßig über die Kontingentzeiträume zu verteilen, entstehen Ein-/Aus-Oszillationen, die schwer und teuer zu load-balancieren sind.
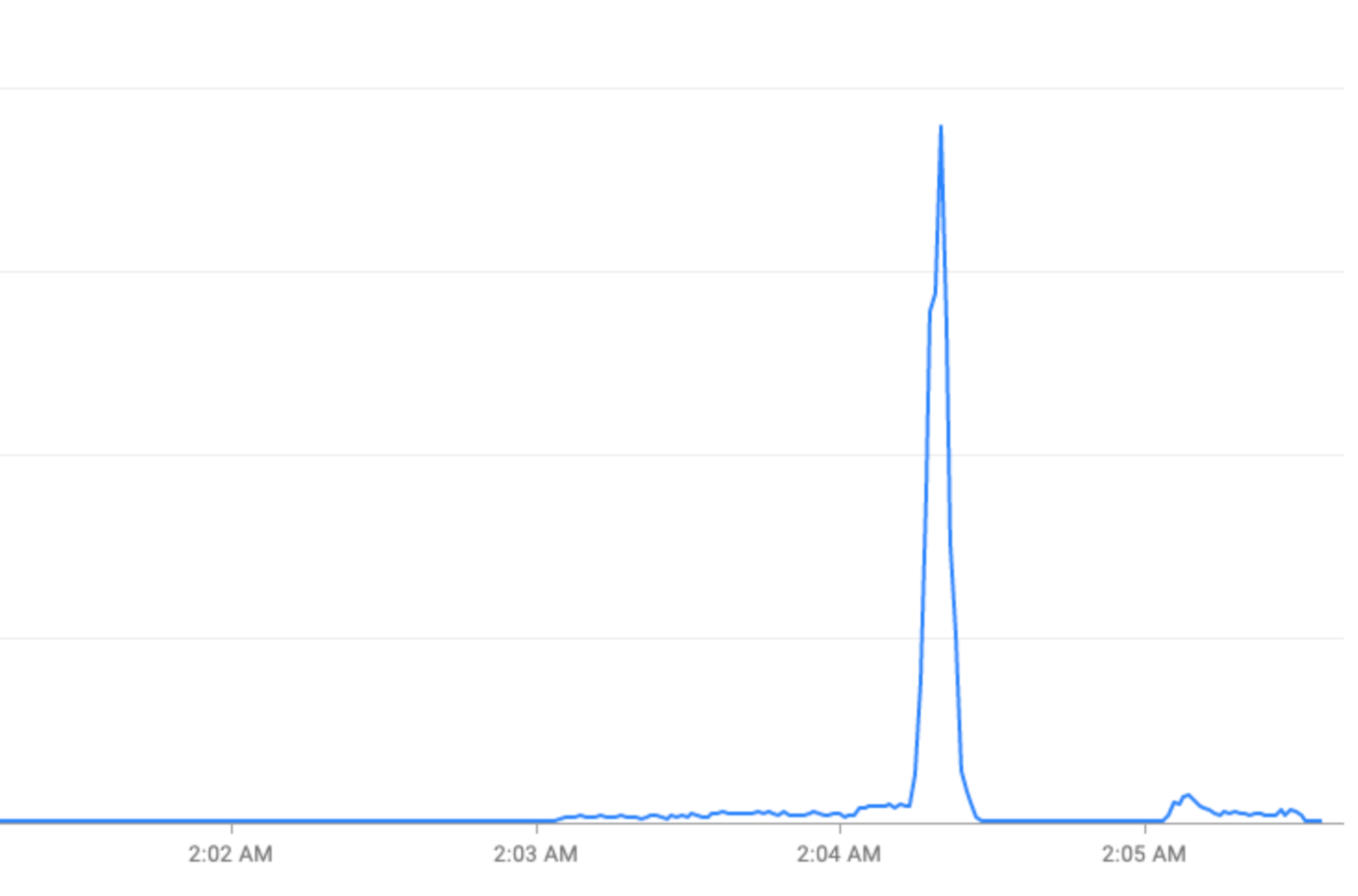
Besondere Ereignisse: Trafficspitzen an Feiertagen (Silvester) oder bei Sportveranstaltungen (FIFA-Weltmeisterschaft).
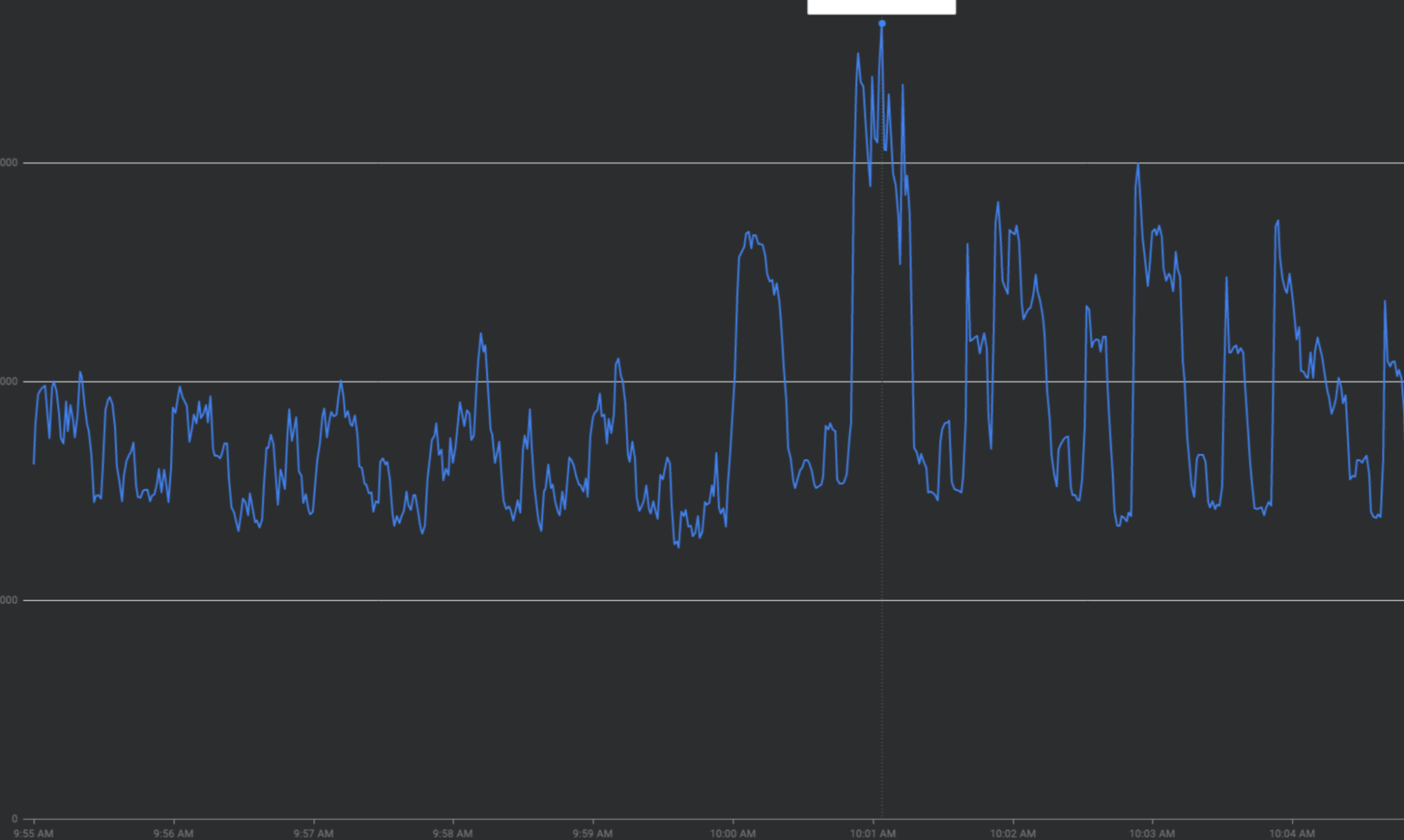
Trafficspitzen durch „Abflachen der Kurve“ beheben
In diesem Abschnitt werden Strategien beschrieben, um Trafficspitzen nach Möglichkeit zu glätten – Strategien zum „Abflachen der Kurve“.
FCM nur für geeignete Anwendungsfälle verwenden
Es gibt einige Anwendungsfälle, in denen die Verwendung von FCM zum Senden einer Benachrichtigung nicht erforderlich oder angemessen ist.
Bei Benachrichtigungen zu Kalenderereignissen können Sie beispielsweise eine lokale Aufgabe in Ihrer App planen, um Benachrichtigungen zu den entsprechenden Zeiten anzuzeigen, anstatt sie von Ihrem App-Server zu senden. Beschränken Sie FCM-Nachrichten auf Kalendersynchronisierungen.
Spitzen vermeiden
Ein Anti-Pattern für die Skalierung besteht darin, FCM-Benachrichtigungen so schnell wie möglich zu senden, anstatt die serverseitige Drosselung anzuwenden. Berücksichtigen Sie Folgendes:
- Müssen alle Ihre Kunden dieselbe Benachrichtigung innerhalb von einer Minute erhalten? Würde ein Zustellungszeitraum von beispielsweise 5 Minuten Ihren geschäftlichen Anforderungen entsprechen?
- Können Ihre Kunden nach Priorität segmentiert werden, um die Spitzen zu glätten?
- Können Ihre Benachrichtigungen im Voraus geplant werden?
Wo immer möglich: Vermeiden Sie Strategien, die dazu führen, dass Ihr FCM-Sendekontingent sofort erschöpft ist, nur um das Muster zu wiederholen, sobald Ihr Token-Bucket wieder aufgefüllt ist. Dieses Zugriffsmuster führt zu Problemen beim Load-Balancing für FCM und die zugehörigen Systeme. Erhöhen Sie den Traffic so schrittweise wie möglich. Erhöhen Sie den Traffic mindestens über einen Zeitraum von 60 Sekunden von 0 auf die maximale RPS. Verwenden Sie für höhere RPS längere Zeiträume.
Traffic zur vollen Stunde vermeiden
Wo möglich: Vermeiden Sie es, Nachrichten innerhalb von 2 Minuten vor oder nach den Zeitpunkten :00, :15, :30 und :45 zu senden.
Serverseitige Drosselung implementieren
Implementieren Sie die serverseitige Drosselung, um den Traffic zu FCM zu überwachen und zu verwalten.
Umgang mit Wiederholungen
FCM ist zwar bestrebt, hochverfügbar zu sein, aber manchmal treten bei einigen Anfragen Zeitüberschreitungen auf oder sie schlagen fehl. Die Gründe dafür sind unterschiedlich. Mit den folgenden Best Practices können Sie das Wiederholungsverhalten optimieren, um Nachrichten so schnell wie möglich zuzustellen und gleichzeitig die Auswirkungen auf die Trafficüberlastung zu minimieren.
Zeitlimits
Legen Sie für Sendeanfragen ein Zeitlimit von mindestens 10 Sekunden fest, bevor Sie sie wiederholen. Die meisten internen Remote Procedure Calls von FCM verwenden ein Zeitlimit von 10 Sekunden.
Fehler
- Bei 400-, 401-, 403- und 404-Fehlern: Abbrechen und nicht wiederholen.
- Bei 429-Fehlern: Wiederholen Sie die Anfrage, nachdem Sie die im Header „retry-after“ festgelegte Dauer gewartet haben. Wenn kein Header „retry-after“ festgelegt ist, wird standardmäßig 60 Sekunden verwendet.
- Bei 500-Fehlern: Wiederholen Sie die Anfrage mit exponentiellem Backoff.
Exponentieller Backoff
Um eine Wiederholungsverstärkung zu vermeiden, implementieren Sie einen exponentiellen Backoff mit Jittering für die Wiederholung von Anfragen. Das Firebase Admin SDK implementiert beispielsweise einen exponentiellen Backoff.
Hier sind einige weitere empfohlene Einstellungen:
- Mindestintervall: Wiederholen Sie eine fehlgeschlagene Anfrage nicht sofort mit FCM. Warten Sie mindestens 10 Sekunden, bevor Sie eine fehlgeschlagene Anfrage wiederholen.
- Maximales Intervall: Legen Sie ein maximales Intervall für das Verwerfen von Anfragen fest, die nicht mehr rechtzeitig sind, anstatt sie unbegrenzt zu wiederholen.
Wenn eine Anfrage kontinuierlich mit exponentiellem Backoff wiederholt wird und auch 60 Minuten später noch fehlschlägt, ist sie entweder falsch als wiederholbarer Fehler kategorisiert oder es liegt ein FCM-Ausfall vor, bei dem Wiederholungen die Situation unbeabsichtigt verschlimmern können.
Rollout- und Rollback-Pläne erstellen und schrittweise Änderungen vornehmen
Wenn Sie umfangreiche Trafficänderungen vornehmen, z. B. den Traffic zu FCM erhöhen oder Traffic über Regionen oder Netzwerke hinweg zu FCM verschieben, schützt ein Rollout-/Rollback-Plan und die Implementierung schrittweiser Änderungen Ihre Nutzer, Ihren Dienst und FCM.
- Ein Rollout-Plan stimmt die Erwartungen der Stakeholder ab. In bestimmten Situationen (siehe unten) sollten Sie Ihren Rollout-Plan im Voraus mit dem FCM-Team teilen, um Überraschungen zu vermeiden.
- Mit einem Rollback-Plan können Sie Eventualitäten berücksichtigen und Mechanismen vorbereiten, um sich schnell und sicher von unerwarteten Fehlern zu erholen.
- Schrittweise Änderungen haben zwei Aspekte:
- Schrittweise Erhöhungen: Die Schritte sollten 1% -> 5% -> 10% -> 25% -> 50% -> 75% -> 100% oder feiner sein. "Soak" (Beobachten Sie das Systemverhalten unter Last) für jeden Schritt 1 Tag bis 1 Woche lang. So können Sie potenzielle Probleme vor dem nächsten Schritt erkennen.
- Schrittweise Erhöhung des Traffics: Wenn Sie den Traffic schrittweise erhöhen, verteilen Sie den Traffic über einen Zeitraum von mindestens einer Stunde. So kann die Load-Balancing-Infrastruktur von FCM Ihren neuen Traffic angemessen skalieren und gleichzeitig das Potenzial für Hotspots und Überlastung minimieren.
Hier ist ein hypothetisches Szenario für die Migration von 500.000 RPS weltweit von der FCM Legacy HTTP API zur FCM HTTP v1 API:
| Woche | Schritt | Strategie für schrittweise Erhöhung |
|---|---|---|
| 0 | 1% Erhöhung | Erhöhen Sie den Traffic innerhalb einer Stunde schrittweise von 0 auf 5.000 RPS für die FCM HTTP v1 API. |
| 1 | 5% Erhöhung | Erhöhen Sie den Traffic innerhalb von 2 Stunden schrittweise von 5.000 auf 25.000 RPS. |
| 2 | 10% Erhöhung | Erhöhen Sie den Traffic innerhalb von 2 Stunden schrittweise von 25.000 auf 50.000 RPS. |
| 3 | 25% Erhöhung | Erhöhen Sie den Traffic innerhalb von 3 Stunden von 50.000 auf 125.000 RPS. |
| 4 | 50% Erhöhung | Erhöhen Sie den Traffic innerhalb von 6 Stunden von 125.000 auf 250.000 RPS. |
| 5 | 75% Erhöhung | Erhöhen Sie den Traffic innerhalb von 6 Stunden von 250.000 auf 375.000 RPS. |
| 6 | 100% Erhöhung | Erhöhen Sie den Traffic innerhalb von 6 Stunden von 375.000 auf 500.000 RPS. |
Hypothetischer Rollback-Plan:
- Wenn die Latenz im 95. Perzentil auf mehr als 500 ms steigt oder die Fehlerrate in einem Schritt länger als eine Stunde 1% übersteigt, verwenden Sie die dynamische Konfiguration, um sofort ein Rollback zum vorherigen Schritt durchzuführen.
- Führen Sie Rollbacks zu früheren Schritten durch, bis die Latenz und die Fehlerrate wieder auf dem normalen Niveau sind.
Wann Sie sich an FCM wenden sollten
Wenden Sie sich über den Firebase-Support an FCM, wenn einer der folgenden Fälle zutrifft:
- Die Standardkontingente entsprechen nicht mehr Ihrem Anwendungsfall.
- Sie ändern Ihre Sendemuster innerhalb von 3 Monaten in einem Umfang von 100.000 RPS weltweit oder 30.000 RPS auf kontinentaler Ebene.