
Ознакомьтесь с этим документом, чтобы принимать обоснованные решения по архитектуре приложений для обеспечения высокой производительности и надежности. В нём рассматриваются расширенные темы, связанные с Cloud Firestore . Если вы только начинаете работать с Cloud Firestore , обратитесь к краткому руководству .
Cloud Firestore — это гибкая масштабируемая база данных для разработки мобильных устройств, веб-приложений и серверов от Firebase и Google Cloud . Начать работу с Cloud Firestore и создавать мощные и многофункциональные приложения очень просто.
Чтобы гарантировать бесперебойную работу ваших приложений при увеличении размера базы данных и трафика, важно понимать механизмы чтения и записи в бэкэнде Cloud Firestore . Необходимо также понимать взаимодействие чтения и записи с уровнем хранения и базовые ограничения, которые могут повлиять на производительность.
Перед разработкой архитектуры приложения ознакомьтесь с рекомендациями, изложенными в следующих разделах.
Понимание компонентов высокого уровня
На следующей диаграмме показаны высокоуровневые компоненты, участвующие в запросе API Cloud Firestore .
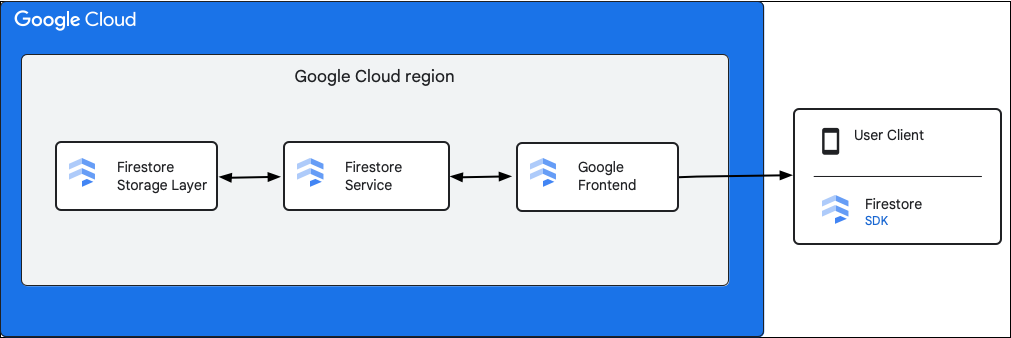
Cloud Firestore SDK и клиентские библиотеки
Cloud Firestore поддерживает SDK и клиентские библиотеки для различных платформ. Хотя приложение может выполнять прямые HTTP- и RPC-вызовы к API Cloud Firestore , клиентские библиотеки предоставляют уровень абстракции для упрощения использования API и реализации передовых практик. Они также могут предоставлять дополнительные функции, такие как офлайн-доступ, кэширование и т. д.
Интерфейс Google (GFE)
Это инфраструктурный сервис, общий для всех облачных сервисов Google. GFE принимает входящие запросы и перенаправляет их соответствующему сервису Google (в данном контексте сервису Cloud Firestore ). Он также предоставляет другие важные функции, включая защиту от атак типа «отказ в обслуживании».
Cloud Firestore
Сервис Cloud Firestore выполняет проверки API-запросов, включая аутентификацию, авторизацию, проверку квот и правил безопасности, а также управляет транзакциями. Этот сервис Cloud Firestore включает в себя клиент хранилища , который взаимодействует с уровнем хранилища для чтения и записи данных.
Уровень хранения Cloud Firestore
Уровень хранения Cloud Firestore отвечает за хранение данных и метаданных, а также за соответствующие функции базы данных, предоставляемые Cloud Firestore . В следующих разделах описывается организация данных на уровне хранения Cloud Firestore и масштабирование системы. Знание того, как организованы данные, поможет вам разработать масштабируемую модель данных и лучше понять передовой опыт работы с Cloud Firestore .
Ключевые диапазоны и разделения
Cloud Firestore — это NoSQL-база данных, ориентированная на работу с документами. Данные хранятся в документах , организованных в иерархии коллекций . Иерархия коллекций и идентификатор документа преобразуются в единый ключ для каждого документа. Документы логически хранятся и лексикографически упорядочиваются по этому ключу. Термин «диапазон ключей» используется для обозначения лексикографически непрерывного диапазона ключей.
Типичная база данных Cloud Firestore слишком велика для размещения на одной физической машине. Существуют также сценарии, когда нагрузка на данные слишком велика для одной машины. Для обработки больших нагрузок Cloud Firestore разделяет данные на отдельные фрагменты, которые могут храниться и обслуживаться на нескольких машинах или серверах хранения . Эти фрагменты создаются в таблицах базы данных блоками ключевых диапазонов, называемыми сплитами.
Синхронная репликация
Важно отметить, что база данных всегда реплицируется автоматически и синхронно. Разделы данных имеют реплики в разных зонах , что позволяет им оставаться доступными даже при недоступности одной из зон. Согласованная репликация в различные копии раздела управляется алгоритмом Paxos для достижения консенсуса. Одна реплика каждого раздела выбирается в качестве лидера Paxos, который отвечает за обработку записей в этом разделе. Синхронная репликация позволяет вам всегда иметь доступ к последней версии данных из Cloud Firestore .
Общим результатом является масштабируемая и высокодоступная система, которая обеспечивает низкие задержки как для чтения, так и для записи, независимо от больших рабочих нагрузок и в очень больших масштабах.
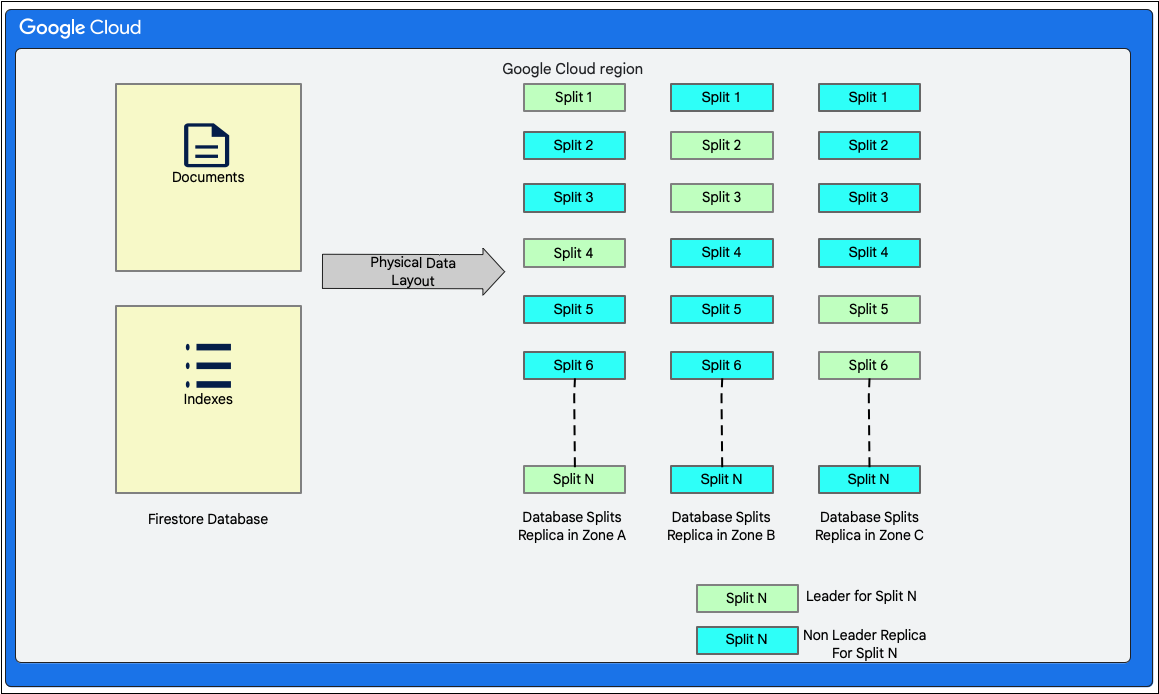
Макет данных
Cloud Firestore — это документоориентированная база данных без схемы. Однако внутри она размещает данные преимущественно в двух таблицах реляционного типа на уровне хранения следующим образом:
- Таблица документов : в этой таблице хранятся документы.
- Таблица индексов : В этой таблице хранятся записи индексов, позволяющие эффективно получать результаты, сортированные по значению индекса.
На следующей диаграмме показано, как могут выглядеть таблицы базы данных Cloud Firestore с разделами. Разделы реплицируются в трёх разных зонах, и каждому разделу назначен лидер Paxos.
Один регион против нескольких регионов
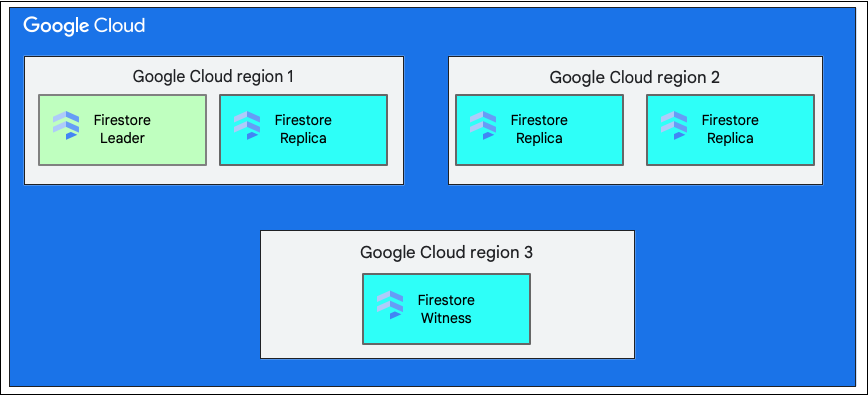
При создании базы данных необходимо выбрать регион или мультирегион .
Единое региональное местоположение — это определённое географическое местоположение, например, us-west1 . Разделы данных базы данных Cloud Firestore имеют реплики в разных зонах выбранного региона, как объяснялось ранее.
Многорегиональное хранилище состоит из определённого набора регионов, в которых хранятся реплики базы данных. При многорегиональном развёртывании Cloud Firestore два региона содержат полные реплики всех данных базы данных. Третий регион содержит реплику-свидетель , которая не хранит полный набор данных, но участвует в репликации. Благодаря репликации данных между несколькими регионами данные доступны для записи и чтения даже при потере целого региона.
Дополнительную информацию о местоположении региона можно найти в разделе Местоположение Cloud Firestore .
Понимание жизни записи в Cloud Firestore
Клиент Cloud Firestore может записывать данные, создавая, обновляя или удаляя один документ. Запись в один документ требует атомарного обновления как самого документа, так и связанных с ним записей индекса на уровне хранилища. Cloud Firestore также поддерживает атомарные операции, состоящие из нескольких операций чтения и/или записи в один или несколько документов.
Для всех видов записей Cloud Firestore обеспечивает свойства ACID (атомарность, согласованность, изолированность и долговечность), присущие реляционным базам данных. Cloud Firestore также обеспечивает сериализуемость , то есть все транзакции выглядят так, как будто выполняются последовательно.
Высокоуровневые шаги в транзакции записи
Когда клиент Cloud Firestore инициирует запись или фиксирует транзакцию любым из упомянутых ранее методов, это выполняется как транзакция чтения-записи базы данных на уровне хранилища. Эта транзакция позволяет Cloud Firestore предоставлять свойства ACID, упомянутые ранее.
На первом этапе транзакции Cloud Firestore считывает существующий документ и определяет изменения, которые необходимо внести в данные в таблице «Документы».
Это также включает внесение необходимых обновлений в таблицу индексов следующим образом:
- Поля, добавляемые в документы, требуют соответствующих вставок в таблицу «Индексы».
- Поля, удаляемые из документов, требуют соответствующих удалений в таблице индексов.
- Поля, которые изменяются в документах, требуют как удаления (для старых значений), так и вставки (для новых значений) в таблице индексов.
Для вычисления мутаций, упомянутых ранее, Cloud Firestore считывает конфигурацию индексирования проекта. Конфигурация индексирования хранит информацию об индексах проекта. Cloud Firestore использует два типа индексов: однополевые и составные. Подробное описание индексов, созданных в Cloud Firestore , см. в разделе Типы индексов в Cloud Firestore .
После расчета мутаций Cloud Firestore собирает их внутри транзакции, а затем фиксирует ее.
Понимание транзакции записи на уровне хранения
Как обсуждалось ранее, запись в Cloud Firestore включает в себя транзакцию чтения-записи на уровне хранилища. В зависимости от структуры данных, запись может включать одно или несколько разделений, как показано в структуре данных .
На следующей диаграмме база данных Cloud Firestore состоит из восьми разделов (обозначенных цифрами 1–8), размещённых на трёх разных серверах хранения в одной зоне, и каждый раздел реплицируется в три (или более) разные зоны. У каждого раздела есть лидер Paxos, который может находиться в разных зонах для разных разделов.
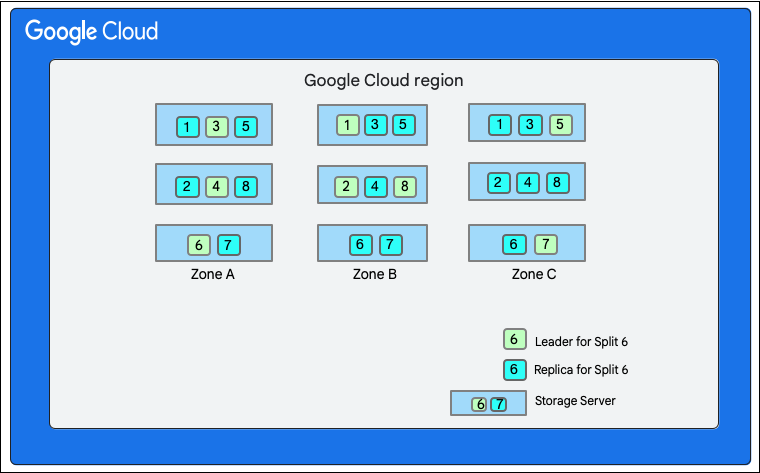 Разделение базы данных Cloud Firestore">
Разделение базы данных Cloud Firestore">
Рассмотрим базу данных Cloud Firestore , содержащую коллекцию Restaurants , как показано ниже:
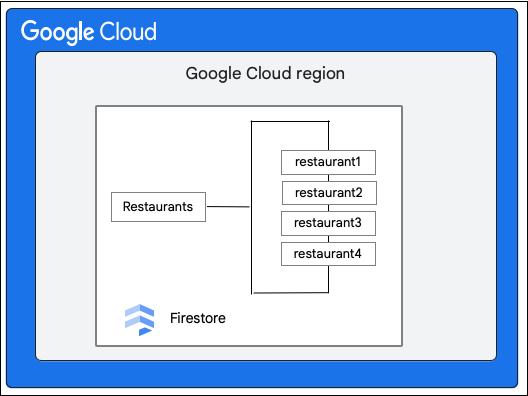
Клиент Cloud Firestore запрашивает следующее изменение документа в коллекции Restaurant , обновляя значение поля priceCategory .
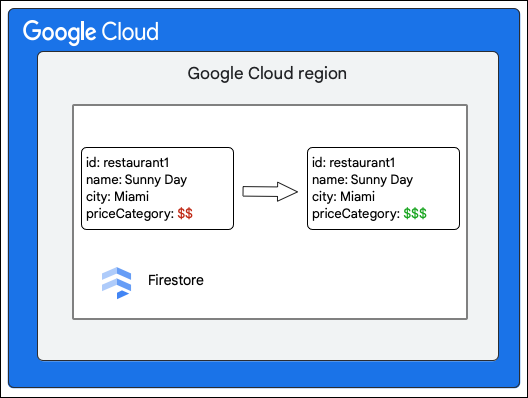
Следующие шаги высокого уровня описывают то, что происходит в ходе записи:
- Создайте транзакцию чтения-записи.
- Прочитайте документ
restaurant1в коллекцииRestaurantsиз таблицы Documents на уровне хранения. - Прочитайте индексы документа из таблицы «Индексы» .
- Вычислите мутации, которые необходимо внести в данные. В данном случае их пять:
- M1: Обновите строку для
restaurant1в таблице Documents , чтобы отразить изменение значения поляpriceCategory. - M2 и M3: Удалите строки со старым значением
priceCategoryв таблице Indexes для нисходящих и восходящих индексов. - M4 и M5: Вставьте строки для нового значения
priceCategoryв таблицу индексов для нисходящих и восходящих индексов.
- M1: Обновите строку для
- Зафиксируйте эти мутации.
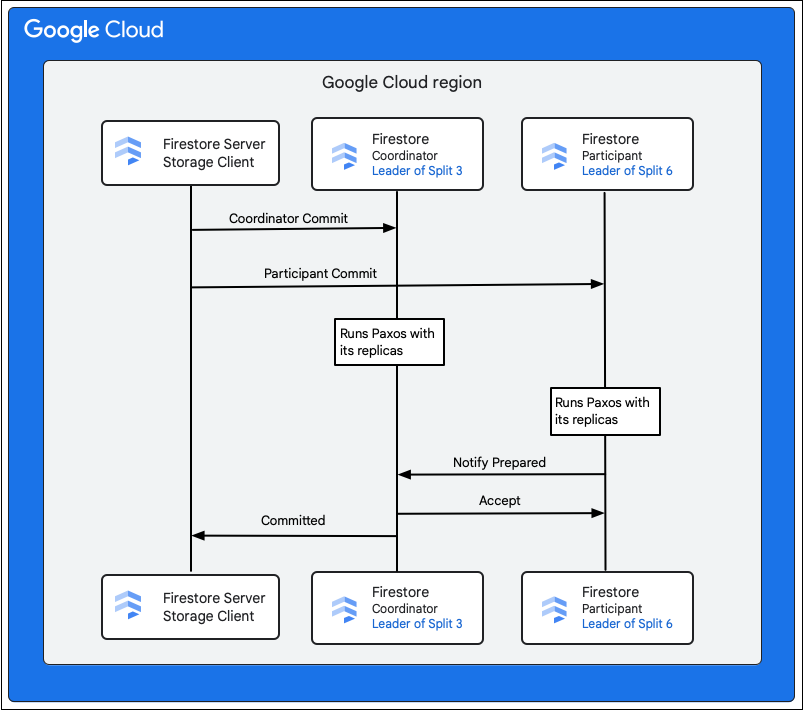
Клиент хранилища в сервисе Cloud Firestore ищет сплиты, которым принадлежат ключи строк, подлежащих изменению. Рассмотрим случай, когда сплит 3 обслуживает M1, а сплит 6 — M2–M5. Имеется распределённая транзакция, в которой все эти сплиты являются участниками . Сплиты-участники могут также включать любые другие сплиты, из которых данные были прочитаны ранее в рамках транзакции чтения-записи.
Следующие шаги описывают то, что происходит в ходе фиксации:
- Клиент хранилища выдаёт коммит. Коммит содержит мутации M1–M5.
- Участниками этой транзакции являются разделы 3 и 6. Один из участников выбирается координатором , например, раздел 3. Задача координатора — обеспечить автоматическое завершение или отмену транзакции для всех участников.
- Руководители реплик этих сплитов несут ответственность за работу, проделанную участниками и координаторами.
- Каждый участник и координатор запускает алгоритм Paxos со своими репликами.
- Лидер запускает алгоритм Paxos с репликами. Кворум достигается, если большинство реплик отвечают лидеру «
ok to commit. - Затем каждый участник уведомляет координатора о своей готовности (первая фаза двухфазного подтверждения). Если какой-либо участник не может подтвердить транзакцию, вся транзакция
aborts.
- Лидер запускает алгоритм Paxos с репликами. Кворум достигается, если большинство реплик отвечают лидеру «
- Убедившись, что все участники, включая его самого, готовы, координатор сообщает всем участникам о результате
acceptтранзакции (вторая фаза двухфазной фиксации). На этой фазе каждый участник записывает решение о фиксации в стабильное хранилище, и транзакция фиксируется. - Координатор отправляет клиенту хранилища в Cloud Firestore ответ о том, что транзакция зафиксирована. Параллельно с этим координатор и все участники применяют мутации к данным.
Если база данных Cloud Firestore небольшая, может случиться, что все ключи в мутациях M1–M5 принадлежат одному разделу. В таком случае в транзакции участвует только один участник, и двухфазная фиксация, упомянутая ранее, не требуется, что ускоряет запись.
Пишет в мультирегионе
При многорегиональном развертывании распределение реплик по регионам повышает доступность, но снижает производительность. Обмен данными между репликами в разных регионах занимает больше времени. Следовательно, базовая задержка для операций Cloud Firestore несколько выше, чем при развертывании в одном регионе.
Мы настраиваем реплики таким образом, чтобы лидерство при разделении всегда оставалось в основном регионе. Основной регион — это регион, из которого трафик поступает на сервер Cloud Firestore . Такое решение о лидерстве сокращает задержку передачи данных между клиентом хранилища в Cloud Firestore и лидером реплики (или координатором для многораздельных транзакций).
Каждая запись в Cloud Firestore также подразумевает взаимодействие с движком реального времени в Cloud Firestore . Подробнее о запросах реального времени см. в статье «Понимание масштабируемых запросов реального времени» .
Понимание жизни чтения в Cloud Firestore
В этом разделе рассматриваются автономные операции чтения в Cloud Firestore , выполняемые не в режиме реального времени. Сервер Cloud Firestore обрабатывает большинство этих запросов в два основных этапа:
- Однодиапазонное сканирование таблицы индексов
- Поиск точек в таблице «Документы» на основе результатов предыдущего сканирования
Чтение данных из уровня хранения выполняется с помощью транзакции базы данных для обеспечения согласованности чтения. Однако, в отличие от транзакций, используемых для записи, эти транзакции не устанавливают блокировки. Вместо этого они работают, выбирая временную метку, а затем выполняя все операции чтения с этой временной меткой. Поскольку они не устанавливают блокировки, они не блокируют одновременные транзакции чтения-записи. Для выполнения этой транзакции клиент хранилища в Cloud Firestore указывает привязку к временной метке, которая сообщает уровню хранения, как выбрать временную метку чтения. Тип привязки к временной метке, выбранный клиентом хранилища в Cloud Firestore определяется параметрами чтения для запроса на чтение.
Понимание транзакции чтения на уровне хранения
В этом разделе описываются типы операций чтения и порядок их обработки на уровне хранения в Cloud Firestore .
Сильные чтения
По умолчанию операции чтения Cloud Firestore строго согласованы . Эта строгая согласованность означает, что операция чтения Cloud Firestore возвращает последнюю версию данных, отражающую все операции записи, выполненные до начала чтения.
Одиночное разделение чтения
Клиент хранилища в Cloud Firestore ищет разделы, которым принадлежат ключи строк, подлежащих чтению. Предположим, ему нужно выполнить чтение из раздела 3 из предыдущего раздела . Клиент отправляет запрос на чтение ближайшей реплике, чтобы сократить задержку кругового пути.
На этом этапе в зависимости от выбранной реплики могут произойти следующие случаи:
- Запрос на чтение отправляется реплике-лидеру (зона A).
- Поскольку лидер всегда актуален, чтение может продолжаться напрямую.
- Запрос на чтение отправляется на реплику, не являющуюся лидером (например, в зону B).
- Разделение 3 может знать по своему внутреннему состоянию, что у него достаточно информации для выполнения чтения, и разделение это делает.
- Разделение 3 не уверено, что оно увидело последние данные. Оно отправляет сообщение лидеру с запросом временной метки последней транзакции, которую необходимо применить для выполнения операции чтения. После применения этой транзакции чтение может быть продолжено.
Затем Cloud Firestore возвращает ответ своему клиенту.
Многораздельное чтение
В ситуации, когда чтение необходимо выполнить из нескольких разделов, один и тот же механизм применяется ко всем разделам. После получения данных из всех разделов клиент хранилища в Cloud Firestore объединяет результаты. Затем Cloud Firestore отправляет эти данные своему клиенту.
Устаревшие чтения
Режим «Сильное чтение» используется в Cloud Firestore по умолчанию. Однако он может привести к увеличению задержки из-за необходимости взаимодействия с лидером. Зачастую приложению Cloud Firestore не требуется чтение последней версии данных, и эта функциональность хорошо работает с данными, которые могут быть устаревшими на несколько секунд.
В таком случае клиент может выбрать получение устаревших данных, используя параметры чтения read_time . В этом случае чтение выполняется в момент, когда данные были получены в момент read_time , и ближайшая реплика, скорее всего, уже подтвердила наличие данных в указанное read_time . Для заметного повышения производительности разумным значением срока устаревания будет 15 секунд. Даже при устаревших данных возвращаемые строки согласованы друг с другом.
Избегайте точек доступа
Разделения в Cloud Firestore автоматически разбиваются на более мелкие части для распределения нагрузки по обслуживанию трафика между дополнительными серверами хранения при необходимости или при расширении пространства ключей. Разделения, созданные для обработки избыточного трафика, сохраняются примерно 24 часа, даже если трафик исчезает. Таким образом, при повторяющихся пиках трафика разделение сохраняется, и при необходимости добавляются новые разделения. Эти механизмы помогают базам данных Cloud Firestore автоматически масштабироваться при увеличении нагрузки или размера базы данных. Однако существуют некоторые ограничения, о которых следует помнить, описанные ниже.
Разделение хранилища и нагрузки занимает время, а слишком быстрое увеличение трафика может привести к высокой задержке или ошибкам, связанным с превышением сроков, которые обычно называются «горячими точками» , пока сервис адаптируется. Рекомендуется распределять операции по всему диапазону ключей, одновременно увеличивая трафик для коллекции в базе данных до 500 операций в секунду. После этого постепенного увеличения трафика увеличивайте его на 50% каждые пять минут. Этот процесс называется правилом 500/50/5 и позволяет оптимально масштабировать базу данных в соответствии с вашей рабочей нагрузкой.
Хотя разбиения создаются автоматически при увеличении нагрузки, Cloud Firestore может разбить диапазон ключей только до тех пор, пока он обслуживает один документ, используя выделенный набор реплицированных серверов хранения. В результате высокие и продолжительные объёмы одновременных операций с одним документом могут привести к возникновению точки перегрузки. Если вы сталкиваетесь с устойчиво высокими задержками при обработке одного документа, следует рассмотреть возможность изменения модели данных для разбиения или репликации данных между несколькими документами.
Ошибки конфликта возникают, когда несколько операций одновременно пытаются прочитать и/или записать один и тот же документ.
Другой особый случай «горячих точек» возникает, когда в качестве идентификатора документа в Cloud Firestore используется последовательно увеличивающийся/убывающий ключ, а количество операций в секунду довольно велико. Создание дополнительных разделений в данном случае не помогает, поскольку весь трафик просто перемещается на вновь созданное разделение. Поскольку Cloud Firestore по умолчанию автоматически индексирует все поля документа, подобные движущиеся «горячие точки» могут также создаваться в индексном пространстве для поля документа, содержащего последовательно увеличивающееся/убывающее значение, например, временную метку.
Обратите внимание, что при соблюдении описанных выше рекомендаций Cloud Firestore может масштабироваться для обслуживания произвольно больших рабочих нагрузок без необходимости внесения каких-либо изменений в конфигурацию.
Поиск неисправностей
Cloud Firestore предоставляет Key Visualizer в качестве диагностического инструмента, предназначенного для анализа закономерностей использования и устранения неполадок, связанных с точками доступа.
Что дальше?
- Узнайте больше о передовом опыте
- Узнайте о запросах в реальном времени в любом масштабе